


Apple publica modelos lingüísticos OpenELM para trabajar sin Internet
Apple ha presentado una nueva serie de modelos de lenguaje OpenELM diseñados para funcionar localmente en los dispositivos sin necesidad de conectarse a servicios en la nube. La serie incluye ocho modelos de distintos tamaños y tipos, que van de 270 millones a 3.000 millones de parámetros.
Estos modelos se han entrenado en enormes conjuntos de datos públicos, que incluyen 1,8 billones de tokens de recursos como Reddit, Wikipedia y arXiv.org. Gracias a un alto grado de optimización, los modelos OpenELM pueden funcionar en portátiles convencionales e incluso en algunos smartphones, como se ha demostrado en dispositivos como PC Intel i9 y RTX 4090 y MacBook Pro con chip M2 Max.
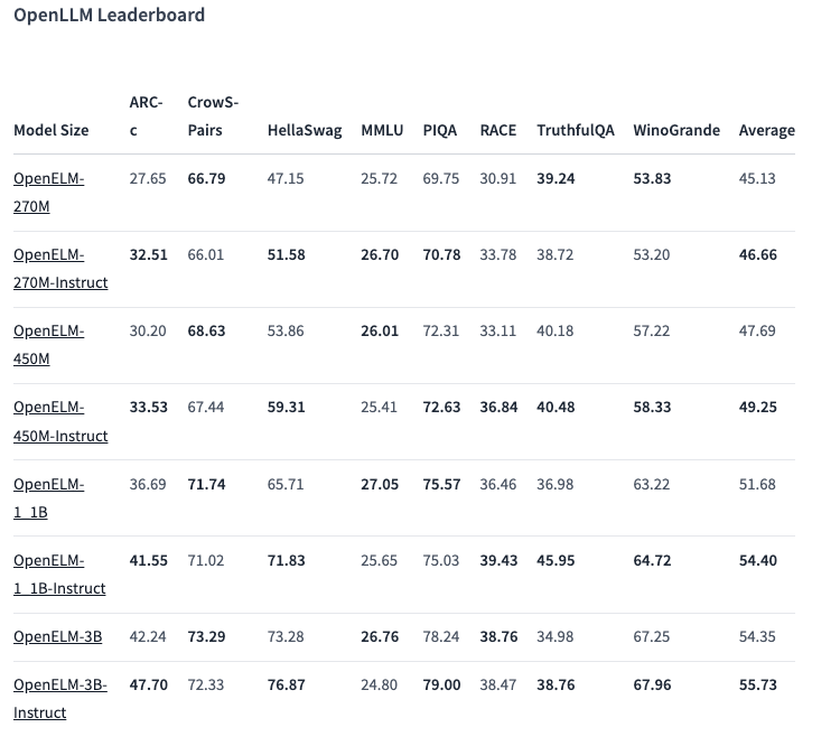
Una de las opciones seleccionadas, un modelo con 450 millones de parámetros, con instrucciones, mostró unos resultados excelentes. El modelo OpenELM-1.1B con 1.100 millones de parámetros demostró ser un 2,36% más eficaz que el modelo GPT similar, OLMo, utilizando la mitad de los datos de entrenamiento.
En la prueba de referencia ARC-C, diseñada para poner a prueba el conocimiento y el razonamiento lógico, la versión preentrenada de OpenELM-3B mostró una precisión del 42,24%. En otras pruebas, como MMLU y HellaSwag, el modelo obtuvo un 26,76% y un 73,28% respectivamente.
Apple también ha publicado el código fuente de OpenELM en la plataforma Hugging Face bajo una licencia abierta, proporcionando acceso a modelos entrenados, puntos de referencia e instrucciones para trabajar con estos modelos. Sin embargo, la empresa advierte de que los modelos pueden producir respuestas incorrectas, maliciosas o inaceptables debido a la falta de garantías de seguridad.